
A typical software application will invariably need to access some kind of data store in order to carry typical CRUD (Create, Read Update, Delete) operations on data.
Typically, this could be some kind of database, file system or any kind of storage mechanism used to store data.
In some cases saving or creating data may actually require persistence to new files or creating a new row in a data table, In other cases saving new data it may actually require a number of interactions with several web-based services.
In this post, we will explore the Repository and Unit Of Work pattern, beyond using it to provide an abstraction over the Entity Framework, in order to gain a better understanding of the two patterns and we'll explore how to use the patterns in order to provide a data layer abstraction in software applications.
In most modern software applications it is becoming increasingly common for the application to have several different data stores from different vendors or even different application Apis. For instance, you may be accessing data from an Oracle HR database, accounting data may be in a SQL server, customer data may be in mySQL based CRM and Product data may be stored in a Cloud Hosted Inventory Management Database.
Your application may be required to perform modifications to all these systems during a course of a transaction. In most cases, you may also have several different data access strategies such as any number of different Object Relational Mappers (ORM) to interact with the various databases.
The challenge for developers in these types of scenarios, is often they don't want to expose the varying different data access logic to their UI layer i.e. Controller or even Business Logic Layers often with the aim of abstracting it in order to reduce direct dependencies.
It is in cases like this that the Repository Pattern comes in extremely useful.
The repository pattern is discussed extensively in the following resources and Patterns of Enterprise Application Architecture and Domain Driven Design
The two books are an essential component of any developers reference materials. I feel the two books work well together in providing Enterprise software developers a thorough grounding on the importance of software patterns and how and when to consider and use them when designing and developing software applications.
Patterns of Enterprise Application Architecture is basically two books in one. The first is a short tutorial on developing enterprise applications, which you can read from start to finish to understand the scope of the book's lessons.
The second part of the book provides a detailed reference to software design patterns themselves. Each pattern provides usage and implementation information, as well as detailed code examples in Java or C#. The entire book is also richly illustrated with UML diagrams to further explain the concepts.

Patterns of Enterprise Application Architecture
Essential reading and desktop reference for all enterprise software developers
Domain-Driven Design provides a systematic approach to domain-driven design, presenting an extensive set of design best practices, experience-based techniques, and fundamental principles that facilitate the development of software projects facing complex domains.
What is the Repository Pattern
Software developers use the repository pattern to separate the logic that retrieves the data and maps it to an entity model from the business logic that acts on the model. This enables the business logic to be agnostic to the type of data that comprises the data source layer.
A Repository mediates between the domain and data mapping layers, acting like an in-memory domain object collection.
Martin Fowler
I've been using a Generic Repository Pattern in some form or fashion for a number of years. The Repository Pattern is an approach to abstract away the details of the data access layer from the rest of the application. Using a Generic Repository is much easier to keep from business logic creeping in where it doesn't belong!
The repository acts as a mediator between the data source layer and the business layers of the application. It queries the data source for the data, maps the data from the data source to a business entity, and persists changes in the business entity to the data source.
Benefits of the Repository Pattern
- Centralization of the data access logic.
- Substitution point for the unit tests.
- Flexible architecture that can be adapted as the overall design of the application evolves.
In order to enable your application to meet all the illities i.e.
- Scalability
- Adaptability
- Testability
- Usability
- Maintainability
- Compatability
- Reliability
- Extensibility
- Portability
- Interoperability
- Reusability
It's important to break up the development of your application into layers. Each layer can then be injected.
This provides levels of abstractions for your various layers in that they do not necessarily explicitly care where the data from each layer is persisted and retrieved from only that it conforms to an explicit data contract.
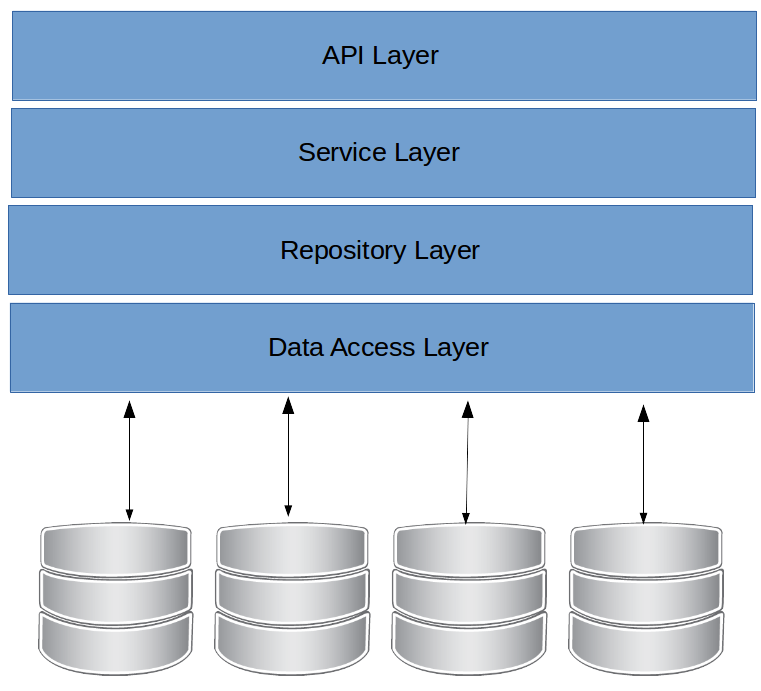
This also enables ease of testing by providing the ability to inject Mock or Fake abstracted classes to provide data.
Unit Of Work
When implementing a Repository pattern it is also important to understand the Unit of Work pattern. Fowler provides an explanation of the Unit Of Work pattern
A Unit of Work keeps track of everything you do during a business transaction that can affect the database. When you're done, it figures out everything that needs to be done to alter the database as a result of your work.
Martin Fowler
The unit of work represents a transaction when used in data layers. Typically the unit of work will roll back the transaction if Commit() has not been invoked before being disposed.
How to implement the repository pattern
In this example, we are going to implement a very simple repository pattern based as an abstraction over Entity Framework core, primarily because historically this has been the most popular use of the Repository pattern.
This serves to highlight the constituent parts of the repository pattern. We'll also establish whether the pattern is still actually suited to this kind of design problem.
The repository pattern is really easy to implement, but it is also incredibly easy to over complicate, confuse and misimplement.
When starting out with the repository pattern, it is best to stick to the principles of YAGNI (You ain't Gonna Need It), so always try to keep your repository simple and clean.
Should you use the Repository Pattern to Wrap Entity Framework?
This is a valid question!
It is also a question that many developers are debating:
- Ditch the Repository Pattern Already
- Repositories on top of Unit Of Work are not a good idea
- Why Entity Framework renders the Repository pattern obsolete?
I've read the posts and I find myself agreeing with them. Everything they say, is indeed valid in certain contexts, but then again in others they may be wrong.
What it all comes down too, is context. It's what is known as in the trade as the Golden Hammer, or the over-reliance on a familiar tool.
if all you have is a hammer, then everything looks like a nail.
I'd be the first to admit, that the repository pattern is not the best solution for every data access strategy, but it can still be the best solution in certain contexts.
Learning how and when to use any software pattern, is still far more important than just learning a pattern and implementing it everywhere
The context most of the above links mainly focus
A few years ago, when the first release of Entity Framework came out - circa 2008 - 09 - it did not lend itself that well to writing unit tests and developers mostly found working with it to be a frustrating experience.
It was around this time, that it became rather fashionable to abstract the use of Entity Framework behind the Repository Pattern and Unit Of Work pattern.
Over the years Entity Framework and in particular Entity Framework Core, like all software has improved and now is easier to use and there is now no need to abstract it in order to write unit tests. In fact, as you'll see in Entity Framework Core In Memory Testing database it's now even possible to use EF Core to write better unit tests!
Taking a high-level view of an ORM, such Entity Framework (EF)
EF Core almost eliminates the need for developers to write SQL queries directly in their code and providing the ability to design and manage the database.
DbContext, within Entity Framework is an example of the Unit Of Work and, IDbSet<T> is a repository providing an abstraction layer over the data access layer.
It is a good idea to take time and review the Entity Framework Core source code and in particular the code for DbContext to see how it all works together
Undoubtedly there will be POCO classes define that reflect the Database entities etc. However, in many cases, these may not always resemble the Business Model of the entities. You may have Domain Entity models which, may actually comprise several Database Entities into one Model.
The issue here is that you end up exposing your Database Object Model to your Middle and even User Interface, which can lead to some crazy misunderstanding and confusion.
Obviously, this is also dependent on the size and purpose of your application, but in most large-scale applications you may want to provide another level of abstraction to make it easier to manage your data layer.
Generally, it is a good idea to expose your Repository layer to a Service layer, which then provides domain entity objects to the UI & Business Layer.
Another use case may be, EF
For instance, in the example, we may want to exclude Asynchronous Functionality to our database. Which is still a valid use case. So we will create a repository abstraction layer that only provides synchronous methods to interact with data, so developers are not tempted to use the asynchronous functionality.
I would
An anti-pattern is a common response to a recurring problem that is usually ineffective and risks being highly counterproductive.
Repository Interface
We will start off developing our Repository by defining an interface it is going to adhere too.
The interface defined here is a simple one with just a handful of methods in order to sufficiently describe and implement the repository pattern.
We will also define a Simple Unit Of Work interface.
The code above is a typical implementation I've seen how some developers will implement a Unit Of Work is just enough to get it working.
Repository
We can simply define our base repository class add the logic to the method it will need to perform. I have kept the code very simplistic and implemented just enough code to get it working for an example point of view.
This is just an example to illustrate how the Unit of Work and the Repository Pattern work together.
The Unit of Work is injected into the repository, as a mechanism to share whichever context it is working with. The job of actually calling the Commit method to save the changes to the database is the responsibility of the calling application and is not in the repository.
You will notice from the example above, we have injected the IUnitOfWork into the Repository class. You may also notice that there aren't any transactions implemented within the repository class, that's because transactions need to be implemented at a higher level because a transaction may contain several operations across different repositories.
The Unit of Work is the area of code in which you may attempt to set the scope that the same IUnitOfWork instance will be used everywhere within a single request. Having a single Unit or Work per request is necessary for the pattern to function correctly.
In theory, you should inject your Unit of work into your repository classes. However, in practice, you may need to deviate.
The above implementation of the repository pattern, is typically a very simplified common implementation of what I have seen how the two patterns have been implemented. It is also primarily the reason why so many of the nasty bugs people have reported occurred!
It is also Cumbersome in a sense because it actually required developers to inject both the IRepository and IUnitOfWork Interface into their application. Which gave the impression that the two patterns operate separately.
An example of the code implementation of a class using the above would look something like this
An architectural representation of this implementation would look something similar to this
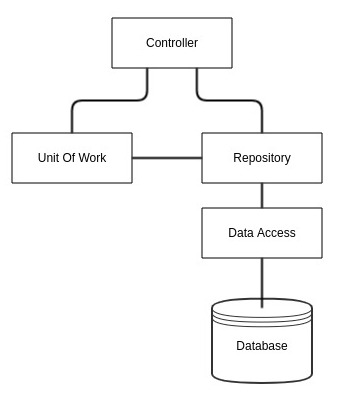
You may be able to discern from the diagram, that this is not the optimal solution and what actually happened here is that we have the potential to introduce bugs into our code due in part that the Repository and the Unit Of Work are two separate objects, which may lead developers to think they are used separately!
In this kind of situation, you're opening yourself to a field of hurt!
Improved Implementation
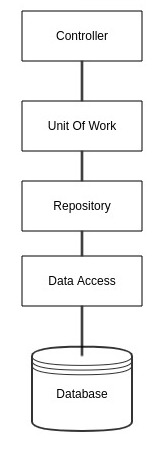
A better approach and essentially the approach as to how Entity Framework takes is to expose the repositories to your application via the Unit Of Work.
The simplified implementation of this looks something similar to this
The
This now this doesn't lead developers down the path of injecting two seemingly unconnected instances into the application and they only need to inject one unit of work to gain access to the repositories.
The eagle eyed among you will notice that this is similar to how entity framework DbContext works
Architecturally, we'll notice that this has cleaned things up a bit and we can get a clearer picture of how all th parts work together.
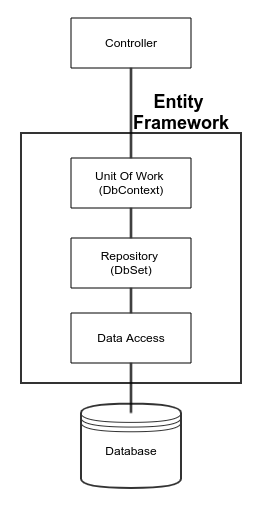
Abstracting the use of Entity Framework
As discussed previously, the most common use of the Repository and Unit Of Work DbContextContollers with Primary Concern that "What if we want to Change
There are a couple issues with this thinking
- The use case for Changing or Swapping ORM's hardly ever comes to fruition!
- There are better patterns to use to mitigate that risk
Entity Framework core is great, but personally I caution against injecting the EF Core context direct into your Controller and often this will have nothing do with wanting to swap ORM's in the future.
The primary reason for this to keep your controller methods clean, small and primarily focused on Presenting data your UI layer.
A typical example of
The pattern which is more ideally suited for such a use case is known as the Service Layer Pattern
A Service Layer defines an application's boundary and its set of available operations from the perspective of interfacing client layers. It encapsulates the application's business logic, controlling transactions and coor-dinating responses in the implementation of its operations.
Many developers confuse the Service Layer Pattern with the Repository Pattern, the primary reason why is that the Service Layer will usually provide an abstraction for the Repository & Unit Of Work pattern in order to de-couple the presentation layer from the Repository.
Why Entity Framework Core is an Implementation of the Unit Of Work and Repository Pattern
The previous implementations of Entity Framework, prior to version 6 and Core, were not exactly a full implementation of the Repository and Unit of Work pattern. All software goes through evolutionary process.
Some design ideas work others don't. Entity Framework has had a fair few of the ones that don't! Which you have to remember, Microsoft or any large software vendor will find out when they release software to vast customer bases, customers will try and do use your products in use cases they had not previously envisioned. It's not that the developers or engineers themselves at poor, its just that customers have alternate thinking.
All software is prone to being over-hyped and expectations are often too high. We have an adage in the industry of "Wait for version 2", in the case of Entity Framework, in my opinion this most definitely meant "Wait for version 6".
Although for the most part, Version 4 was a considerable improvement. It still had a number of little gotchas and quirks. However, the release of version 4, for the most part, negated the use of implementing the Repository and Unit of Work patterns over Entity Framework.
These are the situations and context to which links, defined above, relate to. Primarily the use cases where developers were using the Repository and Unit of Work patterns to abstract the use of Entity Framework because this was seen as a mechanism to be able to switch
I would argue, that Ultimately, this is completely the wrong pattern for the use case, but that is another subject and post entirely.
Conclusion
The Repository pattern is intended to create an abstraction layer between Data Access layer and business layer so it can help to insulate the application from changes in the data store and facilitate automated unit testing for test-driven development.
Entity Framework Core in an implementation of the Unit Of Work and Repository Pattern. Therefore it is not entirely necessary these days to wrap Entity Framework Core in a Unit Of Work/Repository pattern, because fundamentally you're just wrapping an abstraction over an abstraction.

- What is this Directory.Packages.props file all about? - January 25, 2024
- How to add Tailwind CSS to Blazor website - November 20, 2023
- How to deploy a Blazor site to Netlify - November 17, 2023