
In what is curl we discussed one of the most popular command line tools amongst Linux users to download files. In this post we will get to know another popular tool wget.
The name, wget, is derived from combining World Wide Web and the verb Get
GNU Wget is a free software package for retrieving files using the most widely used internet protocols:
- HTTP
- HTTPS
- FTP
- FTPS
It is a non-interactive commandline tool, so it may easily be called from scripts, cron jobs, terminals without X-Windows support, etc. wget has been developed making use of portable C, which can be used on any *nix based system. It is also possible to install wget on both Windows and Mac OS.
Using wget you can download a single file, multiple files, an entire directory or even an entire website.
How to install wget
Most Linux distributions have wget pre-installed by default. However, it is also available in your distributions package manager.
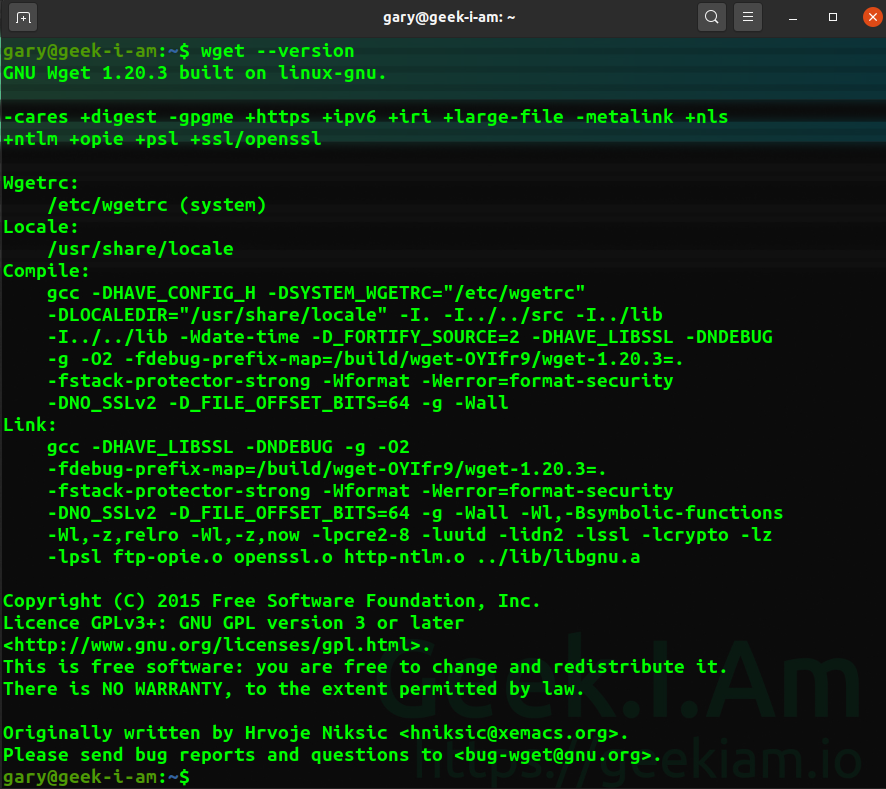
To check whether wget has been pre-installed you can simply use the version check and if present your system will respond with the relevant details.
wget --version
If you're using a Debian or Ubuntu based distribution you can easily install wget making use of the apt package manager.
# Install on Debian based distros sudo apt install wget ## RHEL and Fedora sudo dnf install wget # or sudo yum install wget
no further configuration required and wget is ready for use.
Overview of the wget command
We mentioned previously that wget can be used to download an individual file, multiple files, an entire directory and even entire websites. wget conveniently also attempts to retry a download if a connection drops and resumes from where it left off, if possible, if the re-connection is successful.
Other features include:
- Download files using HTTP, HTTPS, and FTP.
- Download resumption
- Convert absolute links in downloaded web pages to relative URLs.
- Supports HTTP proxies and cookies.
- Supports persistent HTTP connections.
- Can run in the background even when you aren't logged on.
How to download file with wget
All you need to do to download a file(s) with wget is to provide the URL or filepath. wget will default to downloading the file into the directory in which it is called, by default it will use the original name of the file.
We can download a page from this website making use of wget.
## lets create a Gary Woodfine directory to store our file and change into the directory mkdir garywoodfine && cd garywoodfine wget garywoodfine.com/what-is-curl/
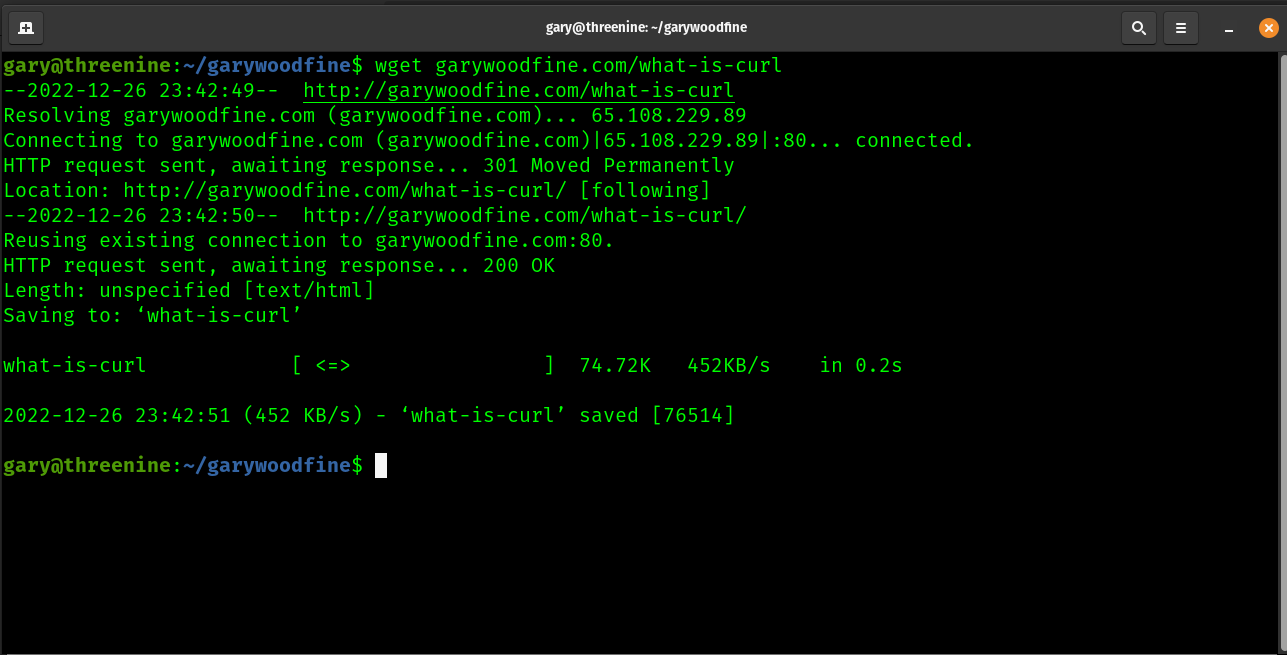
The result is a single index.html file that contains the content pulled from https://garywoodfine.com/what-is-curl/
If you inspect the downloaded file you will see it contains all the HTML to create the web page. Any images and style sheets will not be downloaded.
if you would like to download a file and give it a different name when you download it you can use the -O (uppercase O) option with the filename you would like.
wget -O curl-tutorial.html garywoodfine.com/what-is-curl
How to use wget to download multiple files
Its fairly easy to use wget to download multiple files. For instance, if you create a text file which contains multiple links to files you may want to download you could use wget with the -i to iterate through the file and download each file, as an example lets create a simple text file containin 3 links to download 3 popular web based CMS systems.
nano cms.txt
lets add the following links to the file
https://wordpress.org/latest.zip https://downloads.joomla.org/cms/joomla3/3-8-5/Joomla_3-8-5-Stable-Full_Package.zip https://ftp.drupal.org/files/projects/drupal-8.4.5.zip
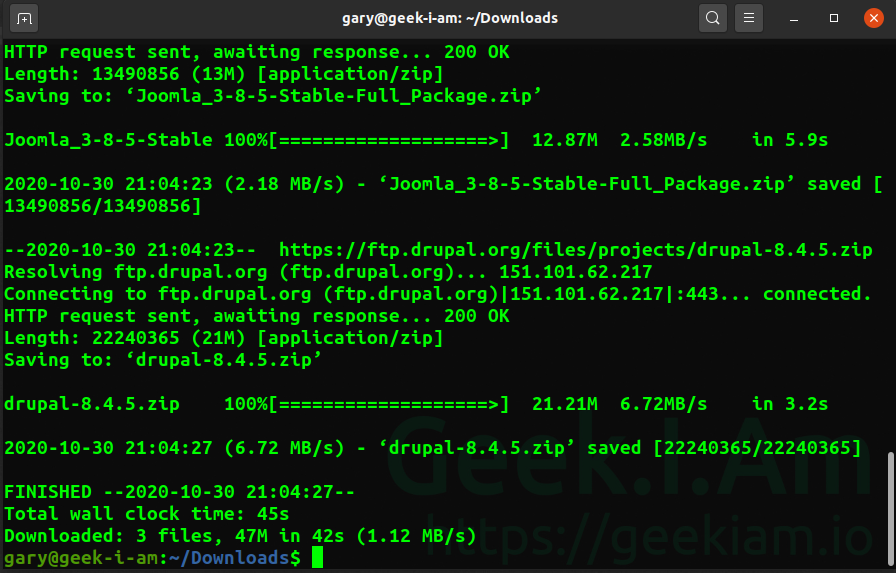
if we save and close the file, we can now use wget to download the files to the directory.
wget -i cms.txt
How to use wget to download files to a specified directory
You may want to download files to a specific directory, which may be a different directory you're running wget in, you can easily do this by making use of the -P switch and providing the path you'd like to use and the source location.
In the example below we want to download the WordPress to our Apache website folder.
wget -P /var/www/html/ https://wordpress.org/latest.zip
How to download an entire website with wget
You can use wget to download an entire website pages recursively up to a maximum of 5 levels deep. By making use of:
wget -r server-address.com
If you would like to incease the levels to recurse, say for instance you know the website has up to 8 levels you use the -l switch with the number of levels to recurse.
wget -r -l8 server-address.com
If you want to create a mirror of an entire public facing website on your machine locally you can easily do using -m mirror option with some additional parameters:
--convert-linksconvert links to ensure all links are relative to the directory--page-requisitesdownloads additional file resources like stylesheets etc.
wget -m --convert-links --page-requisites server-address.com
Download files with FTP
If you need to download files from an FTP based server with a username and password you can easily do so using the following:
wget -r ftp://server-address.com/directory --ftp-user username --ftp-password somepassword
How to run wget as a background task
To get wget to run as a background command leaving you able to get on with your work in the terminal window while the files download. Use the -b switch in the command:
wget -b server-address.com
You can still combine the switches, for instance if you want to mirror a larger site as above you could include the -b option switch.
wget -b -m --convert-links --page-requisites server-address.com
Conclusion
We have explored some of the very common use cases in which wget is used, but the tool is capable of so much more and it is well worth taking the time to read more in the manual. To access the manual simply use the command:
man wget
If you require help with or need more information using a specific command you can use the --help switch
wget --help
- What is this Directory.Packages.props file all about? - January 25, 2024
- How to add Tailwind CSS to Blazor website - November 20, 2023
- How to deploy a Blazor site to Netlify - November 17, 2023