
Developing Micro-services for Application Modernisation projects, often leads developers to develop REST based API systems, due to the fact they are easier to understand and provide the ability to split the components into smaller chunks of resources, each exposed as separate testable and debuggable and usable entry points.
The design of HTTP and the maturity of the tooling with support for URI rewriting and caching make REST based API's a great choice for architectures that need to be both loosely coupled and highly scale-able.
What is ACID ?
Traditional Software Development data models, which appear to indicate or infer that reads and writes are in synchronization when it comes to interacting with the database, in order to maintain the ACID( Atomicity, Consistency, Isolation, Durability) properties pertaining to the data.
ACID is a standard set of properties that guarantee that database transactions are processed reliably and is primarily concerned with how a database recovers from any failure that might occur while processing a transaction. Typically, an ACID-compliant DBMS (Database Management System) ensures that the data in the database remains accurate and consistent despite any such failures.
Atomicity
Atomicity guarantees that either all of the transaction succeeds or none of it does. You don't get part of it succeeding and part of it not. If one part of the transaction fails, the whole transaction fails. With atomicity, its either all or nothing.
Consistency
This ensures that you guarantee that all data will be consistent. All data will be valid according to all defined rules, including any constraints, cascades, and triggers that have been applied on the database.
Isolation
Guarantees that all transactions will occur in isolation. No transaction will be affected by any other transaction. So a transaction cannot read data from any other transaction that has not yet completed.
Durability
Durability means that, once a transaction is committed, it will remain in the system even if there is a system crash immediately following the transaction. Any changes from the transaction must be stored permanently. If the system tells the user that the transaction has succeeded, the transaction must have, in fact, succeeded.
The ACID properties are designed as principles of transaction-oriented database recovery.
Traditional operations such as CRUD (Create, Read, Update and Delete) are mainstream operations carried out on databases regularly. But as business needs become more sophisticated, we turn on to new and efficient ways of working with data. By separating the command and query operations means that operations run on separate logical processes, probably on a separate hardware. A change initiated in a database routes to the command model for updating the database and then later the query model for reading from database.
Command Query Responsibility Segregation (CQRS)
The first time, I encountered the term CQRS, was while reading Implementing Domain-Driven Design

Implementing Domain-Driven Design
Implementing Domain-Driven Design will impart a treasure trove of knowledge hard won within the DDD and enterprise application architecture communities over the last couple decades.
Command Query Responsibility Segregation was first introduced by Bertrand Meyer in Object-Oriented Software Construction as a software architecture is designed to mitigate known caveats of Object-Oriented architecture.
Command Query Responsibility Segregation (CQRS) is a Software Design pattern which at a very high level defines the notion that developers use different models for Read and Update processes. Command and Query which are two operations for reads and writes respectively.
Commands are operations that change the application state and return no data. Queries are operations that return data but do not change application state.
The main use of CQRS pattern using it in high-performance applications to scale read and write operations. Thus, every method should either be a Command or a Query that performs separate actions but not both simultaneously.
The conventional intuitive approach in software development when developing CRUD (Create Read Update Delete) applications, is to use the same mental model. We tend to think in terms of how everything relates to a Single model view of an object.
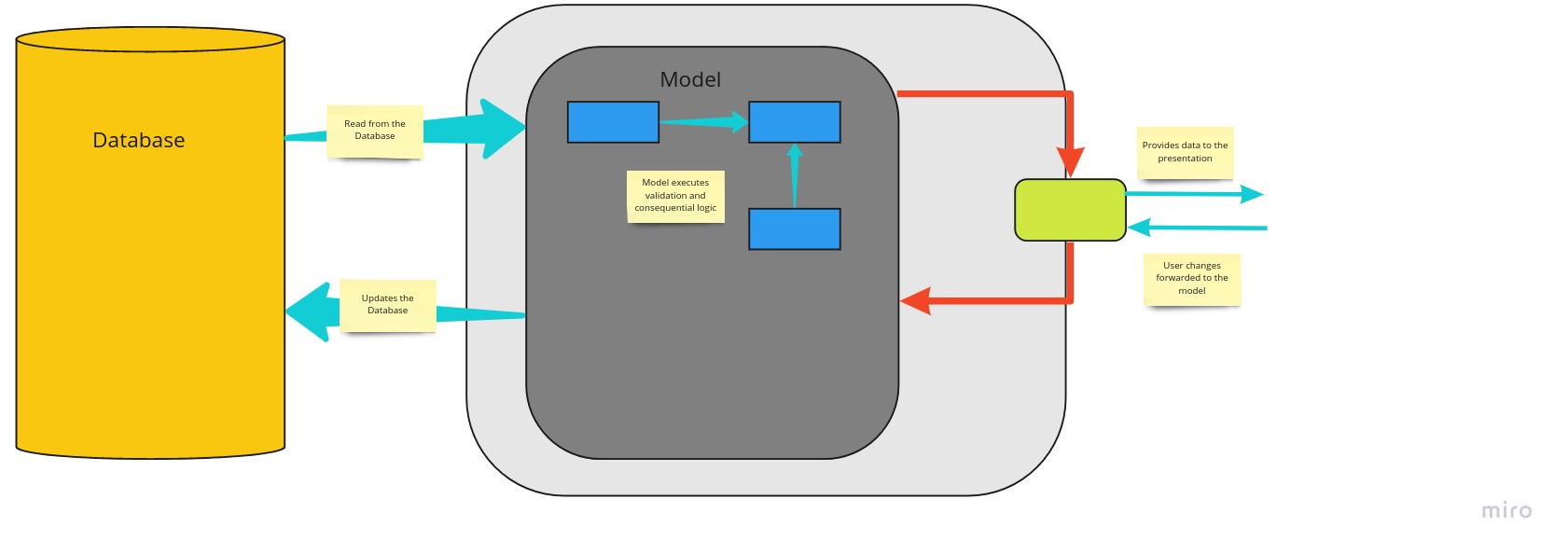
However, over time the Needs and Solutions become more sophisticated and we steadily change our thought processes and we start to look and need information in different ways. Usually collapsing the Model to provide scaled down representations or removing some elements of data that is not needed to satisfy a business need and in other cases we only need to update selective bit of information. We also find that there are different sets of business validation rules that need to applied at different stages of the object update process.
It is at this stage we realise that we need multiple representations of the information and also as more users interact with the information they start to require various alternative presentations of this data, with different representations.
The multi layers of representations of the data introduces a lot of complexity, which often includes a number of similarly named properties etc. The single conceptual representation acts as the main conceptual integration point, and introduces confusion. Having the same conceptual model for commands and queries leads to a more complex model that does neither well.
Using the CQRS we are able to split the conceptual models into separate models for Update and Retrieval , referring to them as Command and Query objects respectively.
Separating the models we inevitably evolve to having to different object models, which can also be executed in different logical processes and even in separate containers and hardware.
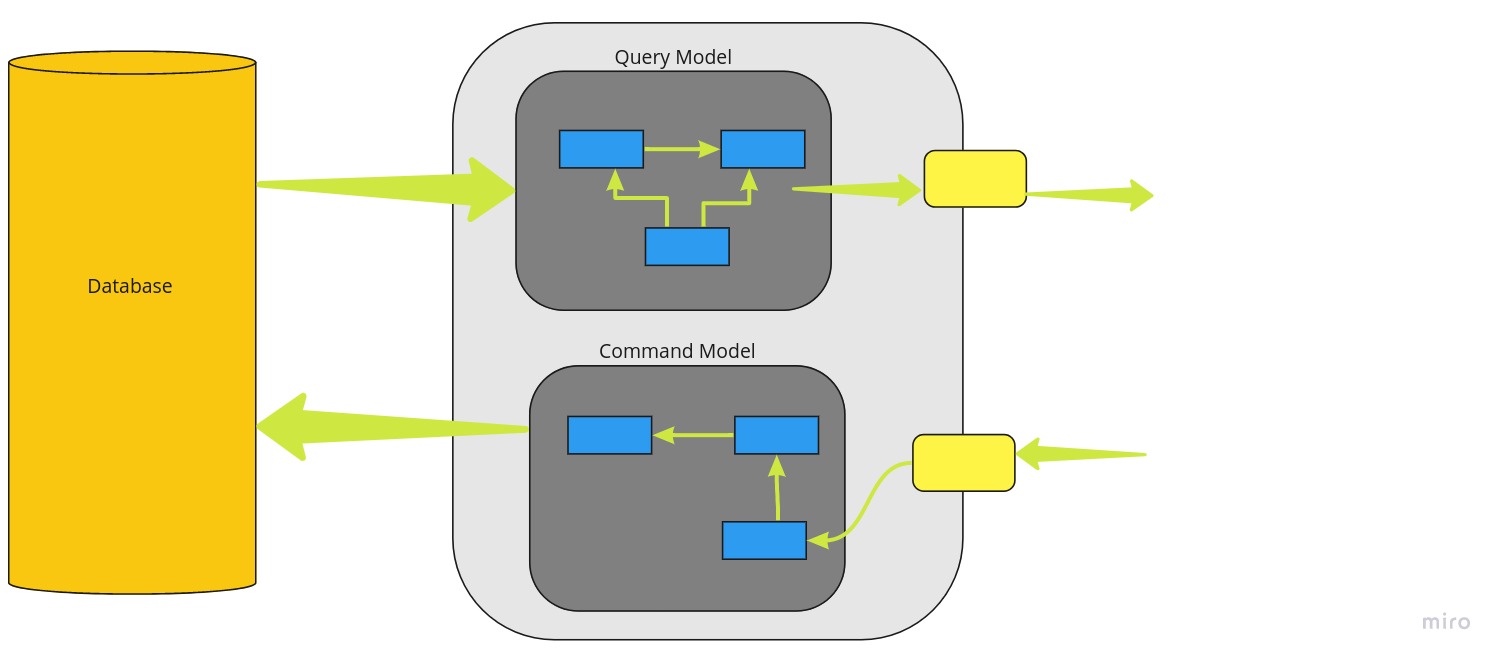
Command
A Command is an operation that can mutate the data without returning a value. Which are essentially any write operations, such as Create, Update and Delete operations.
Query
Query is an operation that will never mutate data and will always return, mostly comprise of read operations.
Where does CQRS fit in with other Architectural patterns
CQRS is a natural fit with the following:
Task based UI systems
- Event-based programming models
- Event-Driven Microservices
- Eventual Consistency
- Domain Driven Design
When to use CQRS
It must be stressed that CQRS is not the golden hammer of software design patterns. Teams can get themselves into more trouble trying to implement CQRS based systems than actually solving their initial problem.
In the world of Event-Driven Microservices CQRS is a natural choice, because ultimately many of these implementations are modelled after the Domain Driven Design concepts of Bounded Contexts, which means each Bounded Context needs its own decisions on how it should be modelled.
CQRS allows you to separate the load from reads and writes allowing you to scale each independently. Which makes it an ideal choice if you are developing high performance applications.
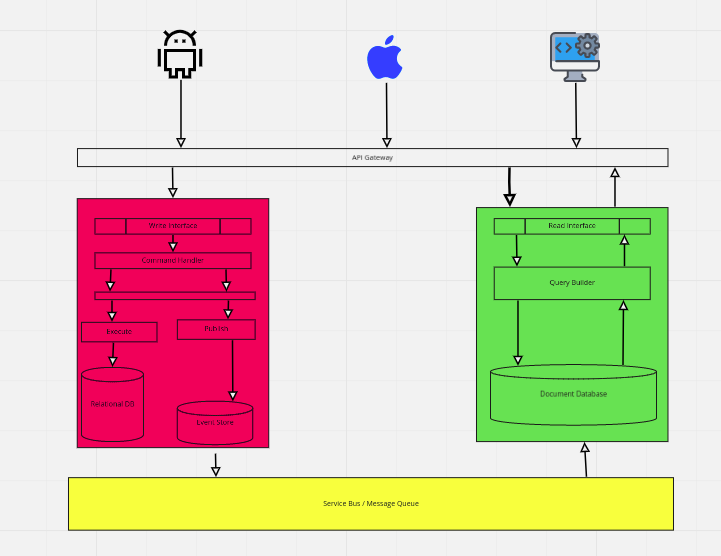
You may want to further separate microservices implementing CQRS pattern into individual services which even have their own databases. For instance you may to use a Document based database for the Read operations in the Read services, and relational database for more efficient write operations in the command based services..
CQRS should also be used with caution and you should remember that while CQRS is a good pattern to have in the toolbox, beware that it is difficult to use well and you can easily chop off important bits if you mishandle it.
A fairly common implementation of the CQRS pattern, is when a web based API, is split into two distinct Microservices 1 Microservice is Responsible for Read Operations and the other is responsible for Write Operations.
This may be because there is more READ operations than there are WRITE operations the services may want to use more cache etc to reduce latency. In this instance an organisation may want to break up the implementation of the API into two separate services but with access via an API Gateway such as Kong Konnect
This obviously does create a bit more overhead when it comes to separating and moving logic from a centralised domain object into multiple action objects.
The Mediator Pattern
A popular software design pattern used when implementing CQRS is the Mediator Pattern, the intent of the Mediator Pattern as defined by the GOF patterns, is to define an object that encapsulates how a set of objects interact. Mediator promotes loose coupling by keeping objects from referring to each other explicitly and it lets you vary interaction independently.

Design Patterns
Elements of Reusable Object-Oriented Software
23 patterns allow designers to create more flexible, elegant, and ultimately reusable designs without having to rediscover the design solutions themselves
Bertrand Meyer devised the principle behind CQRS asserting the following
Every method should be either a command that performs an action, or a query that returns data to the caller, but not both. In other words, asking a question should not change the answer. More formally, methods should return a value only if they are referentially transparent and hence possess no side effects.
Bertrand Meyer
At an object level this means
- If a method modifies the state of the object it is a command and its method must not return a value.
- If a method returns some value, then it is a query and it must not directly or indirectly cause the modification of the state of the object.
Mediator Pattern is used to reduce communication complexity between multiple objects or classes. The pattern provides a mediator class which handles the communication between different classes and supports easy maintenance of the code by loose coupling.
A Mediator perform 2 operations.
- Accept the incoming request
- Handles the incoming request and provide the response.
The Mediator pattern in conjunction with an event-driven persistence layer is one of the best ways to implement CQRS.
Event-driven data persistence is a technique in which events are raised in accordance with a given applications purpose, and the data associated with the given event is consumed by interested services. To enable support for event-driven data persistence in CQRS, there still needs to be intelligence that can mediate read and write behaviour for incoming requests. Data will be dispersed throughout the application in a variety of asynchronous messages that correspond to particular events, there needs to be a mechanism to store all the data for all the events generated.
CQRS is great pattern to consider when developing Event Driven Microservice architecture because an event-driven microservice is a small application built to fulfill a specific bounded context. Consumer microservices consume and process events from one or more input streams, whereas Producer microservices produce events to event streams for other services to consume. Communication between event-driven microservices is completely asynchronous.

Building Event-Driven Microservices
Leveraging Organizational Data at Scale
learn how to leverage large-scale data usage across the business units in your organisation using the principles of event-driven micro-services.
Conclusion
The Command Query Responsibility Segregation pattern is a design technique that is well suited to applications that need to support a high volume of requests made against big data sources. Separating read from write behaviour improves system performance. Enabling systems to scale quickly when functionality or data structures are added.
Used in conjunction with the mediator pattern, CQRS makes the system more flexible and easier to refactor.
Implementing CQRS is powerful but it is definitely not simple, primarily due to Separating data according to purpose means that there is always a risk of compromised data consistency either due to varying degrees of latency on the network or intermittent system failure. Using an event-driven data persistence architecture in which the systems message broker can store every message received for a very long time is a sensible way to go.
CQRS can increase system performance and efficiency. Ensuring the underlying application architecture is loosely coupled and able to be reconstituted to the last know valid state in the event of catastrophic failure.

- What is this Directory.Packages.props file all about? - January 25, 2024
- How to add Tailwind CSS to Blazor website - November 20, 2023
- How to deploy a Blazor site to Netlify - November 17, 2023