
Over the past few years I have become increasingly interested in the concept of Clean Code and Software Craftmanship. However what do these concepts actually mean and why should software developers care about them , or should they actually care about them?
In this post I will discuss different topics related to the concept of Clean Code and what it really means, and hopefully provide some useful insights based on my experience of it out in the wild of enterprise software development.
Almost everything in life is subjective. Get any 3 human beings into a room and you're almost always going to have differing of opinions on any given subject matter. If there is anything us humans do well, it is our capacity for disagreement. Eventually we may arrive at some consensus, but ask any one afterwards and you'll discover that the consensus is nothing more than an agreement for disagreement.
For most of my software development career, I have been convinced there was some unwritten law in force, whereby if you ask any developer about the code quality of another developer, and regardless of whether they had seen it or not, they had to say it was poor!
How can you govern a country which has two hundred and forty-six varieties of cheese?
Charles de Gaulle
Software developers can't even come to an agreement on which programming language is best. I have been a personal witness to one of these great disputes, as I was once on contract where in what I can only think of, as a moment of managerial madness, someone decided to put a bunch of C++, C# and Java Programmers to work all in one room for months. I can tell you, the debate raged on for months, the banter reached insane levels and I don't think an agreement was ever reached!
As a colleague so once eloquently put it, the people in the said room, couldn't even come to an agreement on what they best way to make coffee or to pronounce, the somewhat sugary confectionary of choice in the office. I can say, that Java certainly didn't rank as the preferred coffee!
As far as I know, the Java guys are still coding in Java, the C# guys in C# and the C++ guys are still trying to figure out where the pointers are pointing too and why buffers are overflowing!
What is Clean Code ?
The commonality between these 3 camps is they all believed their choice and preferred programming language enabled them to write Clean Code!
Which can only leave one to assume that Clean Code, is just another highly subjective issue. It is also one, that means something entirely different, depending on where in the Software Development Food chain you sit.
Over the years, I have come to conclude that there are many defintions of clean code developers seem to agree on.
Clean code is code that is easy to understand and easy to change.
The most popular definition of clean code is code that is easy to understand and easy to change. On the face of it this may get heads nodding and chins stroked, but ultimately it's one of those definitions that states something without really stating anything at all.

Clean Code
A Handbook of Agile Software Craftsmanship
software developers irrespective of programming language or discipline should read this book
Following that defintion, absolutely any code, can be classed as clean code. Even the following can be considered clean code. It's easy to understand and we can certainly change it easily.
void FixTheCondition(object aCondition, object someCriteria)
{
if(aCondition != someCriteria)
{
doSomethingToFix(aCondition)
}
}
We could certainly say that the code follows some of the criteria of what makes code easy to understand
- easy to understand the execution flow of the entire application
- easy to understand how the different objects collaborate with each other
- easy to understand the role and responsibility of each class
- easy to understand what each method does
- easy to understand what is the purpose of each expression and variable
The code is easy to extend and refactor, and it's easy to fix bugs in the code base. This can be achieved if the person making the changes understands the code and also feels confident that the changes introduced in the code do not break any existing functionality.
One could argue that for the code to be easy to change:
- Classes and methods are small and only have single responsibility
- Classes have clear and concise public APIs
- Classes and methods are predictable and work as expected
- The code is easily testable and has unit tests (or it is easy to write the tests)
- Tests are easy to understand and easy to change
The above code, fits all of the criteria. We could consider this to be Clean Code, but is it really?
During my career have I seen many interpretations of the exact same code, in hundreds of applications. Even in what some would consider and even sold as scale-able enterprise software. In fact, I would place odds on the fact that if you open most any software application you'll probably find similar examples.
Does this mean the code is actually clean code ?
Who cares about clean code ?
One of the biggest issues within in the software development industry is that, not many of the right people actually care about clean code. It's true that maybe a certain percentage of developers may care about clean code, but from experience they don't all work on the same teams, and most probably not on your team. Those that do care, are in all likelihood engaged in up hill struggles with powers that be.
The truth is, clean code takes time, effort, attention and care, all four values the business sector doesn't really care about. The reason being is that Clean Code falls into the Quality criteria of the Quality Triangle, a variant of what is most commonly known as the Project Management Triangle.
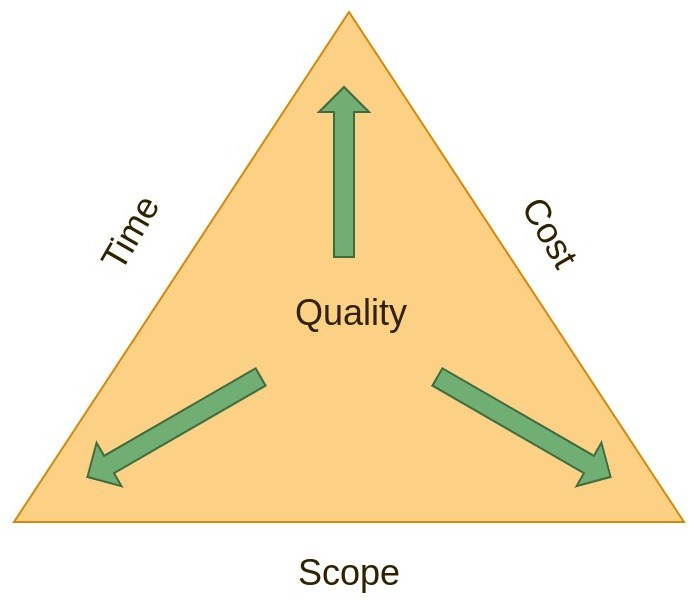
The Project Triangle expresses the Triple Constraint of time, cost and quality or scope that must be managed in project delivery. Each constraint is connected and moving one point of the triangle will impact the other two points.
So you can deliver code and deploy applications fast to meet business objectives, or you can take more time and ensure the quality of the code released. The problem is you can never have both, at some point something has to be dropped. More often than not, in software it's the quality.
The primary reason why, is that code is often the least visible aspect of software development. Sure developers care about it, you'll often hear developers talk of "beautiful code" or even "elegant code" , but very rarely and I'll be the first to admit that I have never heard of a end-user remark on the aesthetics of code. The truth is, they couldn't care less.
The only thing, users generally care about with software applications is that it solves a problem they have . You don't need clean , beautiful or even elegant code to solve problems, this can be done with just code.
Writing Computer software is one of the purest creative activities in the history of the human race. Programmers aren't bound by practical limitations such as the laws of physics; we can create exciting virtual worlds with behaviours that could never exist in the real world. Programming doesn't require great physical skill or coordination like Ballet or Football.
A philosophy of Software Design - John Ousterhout
All programming requires is a creative mind and the ability to organize your thoughts . If you can visualize a system, you can probably implement it in a computer program
Manage Complexity
Many people think the primary task of a software developer is write code to create applications, which is not totally correct, because the primary task of a software developer is to manage complexity. Software developers should use code to hide or eliminate complexity while developing applications.
Complexity is a foe of scale-able, robust and reliable software applications and developers need to ensure they refrain from writing complex code.
Complexity is anything related to the structure of a software system that makes it hard to understand and modify the system.
The key to writing good clean code is to understand the symptoms of complexity and how to avoid it.
1 . Change Amplification
A seemingly simple change requires code modifications in many different places. The goal here is reduce the amount of code that is affected by each design decision, reducing the impact of changes in design decisions requiring many code modifications.
2. Congnitive load
This is level of required information or system knowledge a developer needs to know in order to complete a task. The higher the cognitive load required, increases the chances of bugs arising and time a developer will need to complete the task.
3. Managing the Unknown Unknowns
The third symptom of complexity is that it is not obvious which pieces of code must be modified to complete a task, or what information a developer must have to carry out the task successfully.
Of the three manifestations of complexity, unknown unknowns are by far the worst. This is because an unknown unknown typically means that there is something a developer needs to know, but there is no way for them to find out or even whether there is an issue. In all probability they won't find out about it until a bug appears after they make a change.
Change amplification and cognitive load are annoying and will inevitably lead to an

A Philosophy of Software Design
addresses the topic of software design: how to decompose complex software systems into modules (such as classes and methods) that can be implemented relatively independently.
Causes of Complexity
The causes of complexity are not always directly attributed to bad code, in much the same way that bad code is not always the direct result of bad or even poorly skilled developers. I've witnessed many, highly skilled developers churn out bad code and this has not always been because they just couldn't be bothered, or had some kind of personal vendetta against future maintainers.
Many believe that complexity is caused by two things: Dependencies and Obscurity . In fact, if you spoke to many developers about the causes of complexity, they would probably highlight both these points. The truth is, although they do add to complexity at a code level, they are often not the direct cause of why complexity was introduced in the first place.
There are two hard things in computer science : cache invalidation, naming things and off-by-one errors
unknown
These two causes of complexity within code bases, are not always due to developer choices or actions, but frequently the result of external forces having an impact and forcing developers to make bad decisions. In order to understand and identify these forces, we should first understand the principles behind Dependencies and Obscurity.
Dependency Management
At a high level a dependency exists when a given piece of code cannot be understood and modified in isolation: the code relates in some way to other code and the other code must be considered and/or modified if the given code is changed.
Dependencies are a fundamental part of software and can never be totally eliminated. We often introduce dependencies as part of the software design process. Every time a new class or function is created, it creates dependencies around the API for that class. However, one of the goals of software design is to reduce the number of dependencies and to make the dependencies that remain as simple and obvious as possible.
Obscurity occurs when important information is not obvious, often associated with dependencies, where it is not always obvious that a dependency exists. A leading contributor to obscurity is inconsistency, also often the result of incomplete or inadequate documentation. Obscurity is also often a design issue.
Many organisations and developers will often argue that if a system has a clean and obvious design, then it will need less documentation. Often in the mistaken belief that if there is a need for extensive documentation, then this is a red flag that the design isn't quite right.
Many organisations combat this by implementing Agile methodologies which the mistakenly proclaim, there is no need for documenation because value 2 of the 4 values of the agile manifesto state:
Working Software Over Comprehensive Documentation
Which is often preceded by stating that principle 1 also states :
Individuals and Interactions Over Processes and Tools
This is often exactly the point when dependencies and obscurity creep into code bases, because what is almost always omitted from the code and is not always easy to decipher from reading the code, is the Intent, Reasoning and Objectives.
Dependencies and Obscurity account for the three manifestations of complexity. Dependencies lead to change amplification and high cognitive load. Obscurity creates unknown unknowns, contributing to cognitive load. If we can find design techniques that minimise dependencies and obscurity we could reduce complexity of software.
Iterative Incremental Complexity
Complexity doesn't just happen, like one sudden keyboard stroke, it accumulates gradually. A single dependency or slight obscurity by itself is unlikely to significantly impact the maintainability of a software system.
Complexity comes about because of hundreds or thousands of small dependencies and obscurities building up over time. Eventually there are so many that every possible change to a system is affected by several of them.
It's the incremental nature of complexity that makes it so hard to control and often complex to identify! - Pun literally intended. It's easy for software development teams to fool themselves that a little bit of complexity introduced by a current change is no big deal. The downside, is this becomes culturally permissable and then it accumulates rapidly!
Once complexity has accumulated, it is hard to eliminate since fixing a single dependency or obscurity will not by itself make a difference.
Often once teams find they are overwhelmed by complexity, they often think the only solution is to go for The Grand Redesign in the Sky
Eventually the team rebels. They inform management that they cannot continue to develop in this odious code base. They demand a redesign.
Conclusion
Complexity comes from an accumulation of dependencies and obscurities, leading to change amplification, high cognitive load and unknown unknowns! This often leads to more modifications to implement each new feature and to fix issues created by implementing the previous features.
Developers are required to spend more time acquiring enough information to make changes safely, often with difficulty because they can never find all the information they need because for the most part it doesn't exist!
At it's core, Clean code and the practices are about eliminating or at least attempting to reduce complexity. Although clean code solutions may seem elegant and efficient, they are not always easy and are often the direct result of combating complexity!

- What is this Directory.Packages.props file all about? - January 25, 2024
- How to add Tailwind CSS to Blazor website - November 20, 2023
- How to deploy a Blazor site to Netlify - November 17, 2023