
Many people believe that in order to become a good software developer, engineer or coder that you will need to be able to write good code fast. The truth is, that in order to write good code, you first need to be able read, comprehend and understand code written by others and once you've mastered that you need to be able to collaborate effectively with people, who it is quite possible you will never meet.
It's also a common misconception that software developers are geeks or hackers working in isolation tapping furiously on their keyboards whilst solving deep and complex problems.
The reality is, developers probably spend only 10% of their time actually writing code. This fact, is also discussed in The Mythical Man-Month: Essays on Software Engineering, whereby the average developer will generally contribute on average only 10 lines of code a day.
Professional Software Developers, know that there is a significant difference in rate between adding new lines of code to an existing large project, against starting a new project from scratch. The difference being that when adding new lines to large project, a majority of developer time, is typically spent figuring out relationships between constituent parts of the application code.
Therefore, 90% of developer time, is spent:
- Reading
- Interacting
- Engaging
- Collaborating
- ntegrating
- Re-purposing
- Re-engineering
- Rewriting
This may be code developed by other software developers from all over the world, from different companies and more than likely different years!
In all likelihood, on any given project, the majority of the code contained in it, will be code from many different sources. You will invariably make use of Libraries, Frameworks, Components, Shared Code and at time Copy and Pasted code from other sources. Even the programming language you choose to develop your software is based on code developed by others.
Software development, is very much a team sport, the difference being that in all probability you will never meet or even get to know everybody on your team or contributing to your project. The only aspect of those people you're ever going to physically see, is their code.
In the book Pragmatic Programmer - Your Journey to mastery - Read Review the authors also stress the importance of learning how to use Version Control Systems, as a virtual project wide time machine to enable you to view and return your project to a state when it actually was able to compile and run!
Version control systems keep track of every change you make in your source code and documentation. With a properly configured source code control system, you can always go back to a previous version of your software.
Pragmatic Programmer - Your journey to mastery

The Pragmatic Programmer
your journey to mastery
20th Anniversary Edition (2nd Edition)
Source Code Repository
The primary means developers interact with another and code, is through what is called a Source Code Repository and there are different types. Source Code Repositories can be either Public or Private and sometimes they can be a mixture of both.
repository
- a place or container in which things can be stored for safety
- a place where things are kept for exhibition; museum
- (Commerce) a place where commodities are kept before being sold; warehouse
- a place of burial; sepulchre
- a receptacle containing the relics of the dead
- a person to whom a secret is entrusted; confidant
Private Source Code Repositories
These are generally used by individuals, companies or organisations that only want to share their source code with individuals, companies or other organisations they trust. Often to protect Copyright, Patents or to store source code which is proprietary - meaning code that is for sale.
Public Source Code Repositories
A public source code repositories, are used by developers to share code with anybody, essentially the Public in this context. Typically, software project which make use of Public Source Code Repositories are termed as Open Source Projects, which loosely means the source code is free to see, read and share by anyone.
There are different licensing models available which sometimes could restrict you or even require payment for you to use the software, but generally most Open Source Projects can be free to use too.
Why use a version control system
Version control systems are a category of software tools that help software teams manage change to source code over time. Version control software keeps track of every modification to the code in a special kind of database. If mistakes are made, developers are able to revert changes to essentially turn back time and compare earlier versions of code to not disrupt the code base while minimizing disruption to all team members.
In order to develop quality software, software teams need to be able to track all changes and reverse them if necessary. Version control systems fill that role by tracking project history and helping to merge changes made by multiple people. They also assist in helping to speed up work and help teams to find bugs easier.
Working in distributed teams was made possible thanks to Version Control systems, because they enable developers to work on different parts of the project at the same time and later merge all their work into a single product.
How version control systems changed the software development world
Before version control systems were adopted by software teams, many teams relied on manually backing up previous versions of projects. Manually copying modified files in order to incorporate work conducted by multiple developers on the same project.
Most developers will tell you that any manual task, is going to be error prone, and the manual based task of copying files was indeed very error prone!
Over the years there have been several advancements in version control systems, currently the most popular one among developers has become Git which is a distributed version control system for tracking changes in source code during software development. It has been specifically been designed for coordinating work among programmers, but can also be used to track changes to any set of files!
One of the advantages offered by git, is that every git directory on every computer is a full-fledged repository with a complete history and full version-tracking abilities independent of network access or a central server. Git is also free and open source.
Types of version control systems
Version Control Systems can be broadly classified into two types:
- Centralised Version Control Systems (CVCS)
Examples of centralised version control systems are CVS - Concurrent Versions System and Subversion - Distributed Version Control Systems (DVCS)
Examples of distributed version control systems are Git, Mercurial and Bazaar
The fundamental difference between a DVCS and CVCS relates to the approaches taken by the systems to managing their repositories and they user workflows employed to getting content into the server-side part of the system.
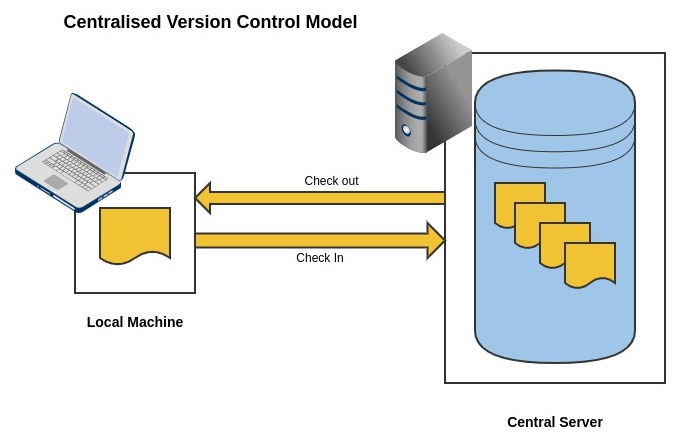
Central Version Control Systems
In a centralised version control system model, there is a central server that contains all the repositories with all the history, versions and changes of the system over time. A single source of truth, in that the server is a container of all the repositories.
The user workflow when working with a centralised model dictates that if a user wants to work on a file(s) in one of the repositories, they will need to connect to the server via a client and retrieve file(s) they want to work on. They are then able to make whichever edits required to the files, once they have completed their changes, they then submit the file(s) back the server. The file differences from the previous version are determined and stored in the repository as updates.
The users are dependent on the central server. If the server is unavailable for whatever reason, users cannot make any source management operations.
Distributed Version Control Systems
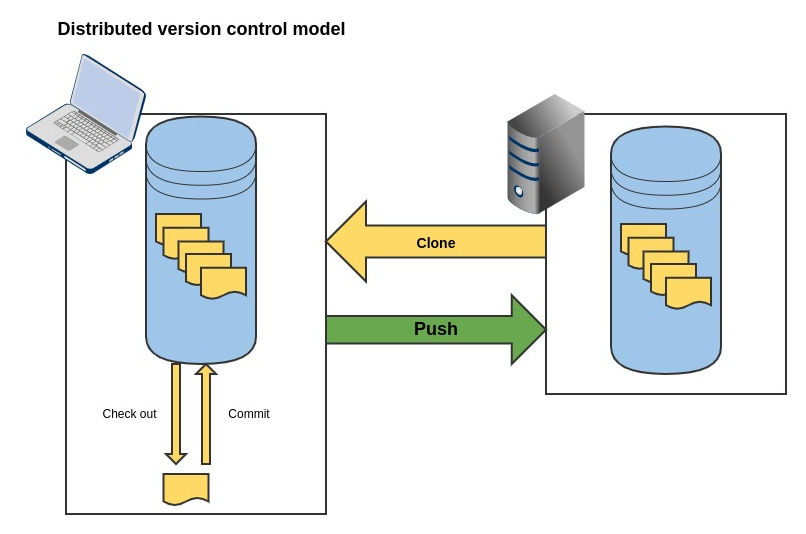
In a distributed version control model, a remote server holds contains the shared repositories. However, when users want to make changes instead of getting the individual files they want to work, they pull down the entire repository in a process which is defined as cloning. The copy that comes from the remote server has all the content and includes all the history of the changes made to files up until the point when the copy was created.
Any changes that are made to the local repository is called a commit which is a similar concept to a check-in, but it is only made to the local instance at this point.
Once the user has completed all the changes they want to make to the local instance, they can then push their changes to the remote server.
The key difference is that the users are performing their source management operations against the local copy repository. It is only until the users push the changes back to the remote are they required to connect to the remote server. The connection between local and remote is not constant and is only activated when synchronisation between the two repositories is required.
Distributed version control with Git
When working with git you will often need a central repository that will act as a source of truth for all developers to to sync up to. In most cases this may be a Cloud-based service such as Github, Gitlab, BitBucket or a private server on the internet. Whichever one your team uses, the role of this central repository is to provide your team with a Remote central server for your team to Push and Pull changes to source code.
Git Version Control
In what is git we discuss git in detail, its origin and and what makes it unique and why it has become popular with developers the world over.
We also guide you through the process of How To Install Git On Linux and how to do the basic amount of configuration required to start working with git.
What are the benefits of version control systems
One of the biggest benefits of version control systems is that they dramatically reduce risks of developers losing or corrupting source code. It also helps developers to collaborate with each other more efficiently and effectively. By enabling developers to quickly and easily share code.
There are some a number of additional benefits of using Version Control systems, however I will discuss just 2 of the most important aspects.
Branching and merging
Having team members work concurrently is of fundamental importance, however even lone individuals can benefit from the ability to work on independent streams of changes. Creating a "branch" in VCS tools keeps multiple streams of work independent and separate from each other while also providing the facility to merge that work back together, enabling developers to verify that the changes on each branch do not conflict. Many software teams adopt a practice of branching for each feature or perhaps branching for each release, or both. There are many different workflows that teams can choose from when they decide how to make use of branching and merging facilities in VCS. The branching model used by Git enables cheap local branching and flexible branch publishing, allowing to use branches for context switching and for sand-boxing different works in progress.
Traceability
Being able to trace each change made to the software and connect it to project management and bug tracking software such as Jetbrains Space, and being able to annotate each change with a message describing the purpose and intent of the change can help not only with root cause analysis and other forensics. Having the annotated history of the code at your fingertips when you are reading the code, trying to understand what it is doing and why it is so designed can enable developers to make correct and harmonious changes that are in accord with the intended long-term design of the system. This can be especially important for working effectively with legacy code and is crucial in enabling developers to estimate future work with any accuracy. The fact that the whole history is accessible allows for long-term undo, rewinding back to last working version, and so on. Tracking ownership of changes automatically makes it possible to find out who was responsible for any given area of code, and when each change was done. You can compare different revisions, go back to the revision a user is sending a bug report against, and even automatically find out which revision introduced a regression bug. The fact that Git is tracking changes to the tips of branches with reflog allows for easy undo and recovery.
Basic Concepts of version control
Tracking changes
The primary and most crucial function of version control systems is to track changes that happen with directories and files within a software development project. Depending on the version control system, this could vary from knowing a file changed to knowing specific characters or bytes in a file that have changed.
In most cases, you specify a directory or set of files that should have their changes tracked by version control.
This can happen by checking out (or cloning) a repository from a host, or by telling the software which of your files you wish to have under version control.
The set of files or directories that are under version control are more commonly called a repository.
Each change you make to a file will be tracked behind the scenes. Once you are finished making your changes, and prepare to save your changes to a repository, a process commonly refered to as Commit or Check-In , then you version control system will enable you to review your changes and compare them against the existing files.
Commit
Each change to a file is tracked automatically, this may include editing a file, moving a file, deleting a file, reformatting a file or just about any change that could be made to a file. Instead of recording each change individually, the version control system will wait for you to submit your changes as a single collection of actions.
As mentioned previously, in version control, this collection of actions is known as a commit. A unique feature of Git is that it enables explicit access to the staging area for creating commits. This provides additional flexibility to managing your working area and deciding on the shape of a future commit.
Revisions and Change sets
After a Commit has been completed, then the changes are recorded in what is referred to as a ChangeSet and assigned a unique revision ID. The ID may be in the form of a simple incremented number i.e. (1, 2, 3 ……… 1234567708 etc), but typically in git and other popular
distributed version control systems it is a Unique Hash code.
` shell script
An example of a system generated hash code
39abc87d1234cr890u8sd9709sdfa9878d9s0df
A change set will include a reference to the person who made the commit, when the change was made, the files or directories affected, a comment and even the changes that happened within the files.
For collaboration, having the ability to view past revisions and change sets is a valuable feature to see how a project has evolved and to changes to the code base. Each version control system has a formatted way to view a complete history of each revision and change set in the repository.
Updates
To ensure you are always working with the latest version of the code, you will need to ensure you always update your local repository. Getting the latest changes from a repository is as simple as doing a pull or update from another computer. When an Update or Pull is requested, only the changes since your last request are downloaded.
Conflicts
There may be instances, when a colleague, team member or other collaborator makes to a change to the same file(s) that you are working on. Version control systems provide a way to view the difference between the conflicting versions and enabling you to make a choice. You can either edit the files manually to merge the options, or allow one revision to win over the other, or carry out a mix of both in a process which is referred to as Conflict Resolution
Branching and Merging
There are some cases when you want to experiment or commit changes to the repo that could break things elsewhere in your code in what is referred to as Feature development. Instead of committing this code directly to the main set of files usually referred to as trunk , master , default or main, you can create something called a Branch.
A branch enables you to create a copy of the repository that you can modify in parallel without altering the main set. You can continue to commit new changes to the branch as you work, while others commit to their branches or the main code repository without changes affecting each other.
Once you’re satisfied with the experimental code, you want to make it part of the trunk or master again.
This is where merging comes in. Since the version control system has recorded every change so far, it knows how each file has been altered.
Merging a branch with the trunk or master or other branches, your version control system will attempt to seamlessly merge each file and line of code automatically. Once a branch is merged it then updates the Main branch with the latest files.
- What is this Directory.Packages.props file all about? - January 25, 2024
- How to add Tailwind CSS to Blazor website - November 20, 2023
- How to deploy a Blazor site to Netlify - November 17, 2023