
A common business requirement to extract meaningful data from unstructured data sources. For instance, data in Word Documents, Text Files or even social media streams.
A common scenario of this is within the recruitment industry whereby agencies may need to trawl a large dataset of Resume's or as we like to call them in the UK CV's (Curriculum Vitaes) for mentions of specific skills or Job Titles etc
Scouring large corpuses of unstructured data is an ideal task for AI or commonly Machine Learning, that developers are tasked with implementing.
This type of task is referred to as Named Entity Recognition.
What is a Named Entity Recogniton
Named Entity Recognition (NER) is a sub task of Natural Language Processing (NLP) , which is focused on the information extraction, to locate and classify entities text.
I have previously written a post providing an Introduction to Natural Language Processing which provides further information and a simple example how to implement it using Python
NER is a process where an algorithm analyzes string of text as input and identifies relevant text from large coprus of documents or data for instance - People, Places, Organizations, Product Codes, Skills, Job Titles, SKU, Email addresses, Urls etc.
The string of text can literally be any source of data that can be represented as a string, for instance, text extracted from Word Documents, Web Pages, JSON, XML. If you can you can convert to string or store in a Text based file you can do prefrom NER.
NER is particularly useful when building search based Algorithms, to help improve performance and indexing of documents.
Keywords or entities are condensed form of the content are widely used to define queries within information Retrieval (IR). You can extract keyword or entity by various methods:
- TF-IDF of word
- TF-IDF of n-grams
- Rule based POS tagging.
One of the most common use cases Named Entity Recognition involves automating the recommendation process. Recommendation systems dominate how we discover new content and ideas today. For example, Netflix developed an effective recommendation system by making their platforms more engaging and event addictive automatically suggesting new Films, TV Shows and documentaries based on ones who have previously watched.
The business application and advantages of NER are immense and it really is helpful if developers know how to implement these specific tasks. You don't have to be a Data Scientist or even a Mathematical genius to implement these types of tasks.
There are currently a number of tools developers can use to perform NER tasks and AWS enable developers to make use of a cloud based service, AWS Comprehend, which enabling developers to use and create NER models without having to get too involved with the Data Science aspects.
If you can call a Cloud Service and possibly handle a Spreadsheet then this is all you need to know to get started.
What is AWS Comprehend
Amazon Comprehend uses natural language processing (NLP) to extract insights about the content of documents. Amazon Comprehend processes any text file in UTF-8 format. It develops insights by recognizing the entities, key phrases, language, sentiments, and other common elements in a document. Use Amazon Comprehend to create new products based on understanding the structure of documents. For example, using Amazon Comprehend you can search social networking feeds for mentions of products or scan an entire document repository for key phrases. Read more about AWS Comprehend
AWS Comprehend can do a lot more than NER but for the purpose of this article we're going to explicitly focus on implementing NER in order to detail how to make use of this AWS Offering using .net core.
When I started out with AWS Comprehend, I found the documentation although somewhat useful it was also full or gaping holes and in general a rather frustrating experience.
Basic NER Implementation with AWS Comprehend and .net core
In this example I will create a very simple class that will call AWS Comprehend service providing some text and extract the entities that are mentioned in that text.
We'll create a simple .net core Console Application and add a reference to the AWSSDK.Comprehend nuget package. I will be using Jetbrains Rider as I primarily develop .net core applications on Ubuntu Linux.
You may also want to ensure you have the AWS CLI installed, if not you can check out How to install and configure AWS CLI on Ubuntu.
To add a reference to AWSSDK.Comprehend you can use the CLI
dotnet add package AWSSDK.Comprehend
We can then create our simple class which we'll use to preform a Basic Entity Detection.
public class BasicEntityDetection
{
private readonly AmazonComprehendClient client;
public BasicEntityDetection()
{
client = new AmazonComprehendClient(Amazon.RegionEndpoint.USWest2);
}
public List<Entity> Get(string inputText)
{
DetectEntitiesRequest detectEntitiesRequest = new DetectEntitiesRequest
{
Text = inputText,
LanguageCode = "en"
};
var response = client.DetectEntitiesAsync(detectEntitiesRequest).Result;
return response.Entities.ToList();
}
}
The purpose of this class, is demonstrate the basics of calling the service. We're not going to win any Clean Code contests, but we will be able to provide an overview of the components required.
We create the an instance of AmazonComprehendClient and in my case I'm explicitly defiing the Region to be the UK, as it is one of the regions where Comprehend is supported and the region where I'm based.
We have the Get Method which has an InputText argument which we'll provide as the text that needs to be analysed, within the method we create and configure the request that we are going to send to Comprehend.
We then send the request. AWS Comprehend client only exposes Asynchronous methods, but we're not at this stage going to be making use of them so therefore we have explicitly get the result . We then simply return the list of detected entities to our calling application.
Our calling application in this instance will look something similar too.
class Program
{
static void Main(string[] args)
{
var text = "Hi, my name is Gary Woodfine and I'm a UK based full stack developer. I am highly skilled in C#, .net core, ASP.net, PHP, Python, Laravel among a number of technologies. I have my own company, threenine.co.uk which I work for providing software solutions to complex business problems. I run a popular tutorial based website, https://garywoodfine.com . I like to eat coconuts on a beach and drink pina coladas in the rain ";
var detect = new BasicEntityDetection();
var entites = detect.Get(text);
foreach (var e in entites)
Console.WriteLine($"Text: {e.Text}, Type: {e.Type}, Score: {e.Score}, BeginOffset: {e.BeginOffset}, EndOffset: {e.EndOffset}");
Console.WriteLine("Done");
}
}
The output will look similar to
This works great for a really basic NER Extraction , Comprehend correctly identifies me as a PERSON but as you can tell it has labled skills as OTHER , even the two URL's contained in the Text as OTHER.
It is common for organisations to want to customize NER extraction to identify specific terms in text. For instance a recruitment agency may want to identify Skills in a CV or even a Alcoholic Drinks company may want to extract specific cocktails preferred by Full Stack Developers in social media feeds. This is where having the ability to train a Custom NER extractor can come in handy.
AWS Comprehend makes it possible to customise Comprehend to preform customised NER extraction, there are two methods of training a custom entity recognizer :
- Using annotations and training docs
- Using entity list and training docs
They both preform exactly the same action however using annotations and training docs is more accurate. However, it does actually take more time to implement. Due to the need to annotate, i.e. Label your training data, which can be a very time consuming and boring task.
In my personal experience, I prefer to use both I essentially start off using an entity list training documents and I then use the data from that phase to start building up a dataset to train using annotations and training docs.
In this post, I will walk through this process and illustrate how you can make use of AWS comprehend to train a custom recognizer to do both.
Train AWS Comprehend using entity list and training docs
In this example we are going to train AWS Comprehend to extract a list of skills in from a corpus of Word Documents. When developing Machine Learning (ML) and Artificial Intelligence (AI) applications the first thing you'll learn is that the more data you have available the better your ML algorithms will be able to learn. So it's important to get as many examples of the type of documents your application will be used to scan so you can use them as examples.
Fortunately in my case, I have a large corpus of sample documents I can use. We also need to extract the data contained in these documents to simple text files, fortunately Python makes this extremely easy to do so which I have detailed How to convert Word Documents to Text Files with Python .
Once you have your training sample documents prepared you should load them up a folder in your S3 Storage, you should also have AWS CLI installed and Configured to make things easy.
After your training documents have been uploaded we can now start creating an initial Entity List CSV file that we will use. Start Identifying our Entities.
I use LibreOffice Calc to do this, but you can use any application like MS Excel, Apple Numbers or even a simple text file and a text editor do so.
The important aspects of this CSV file is that it should be UTF-8 encoding and follow the simple guidelines as defined AWS Comprehend Entity List
A text based snap shot of my sample document looks similar to then one below, but bare in mind I have constructed an entity list of over 500 + technology skills as my initial list but I have not included them all for the sake of brevity
Important aspects to note here is that I have decided to call my custom Entity I want to identify as TECHNOLOGY.
For simplicity I usually just use the AWS Comprehend UI to start training my models, because at the initial training phases a lot could go wrong and for this phase I don't really want to be writing custom code at this stage, however as things progress in this cycle I usually start developing code to automate this process making use of the AWS.Comprehend API.
I won't discuss in detail how to use the AWS Comprehend UI it is actually quite self explanatory, but I'll just provide the screen shots of how I configured my Initial technologyRecognizer
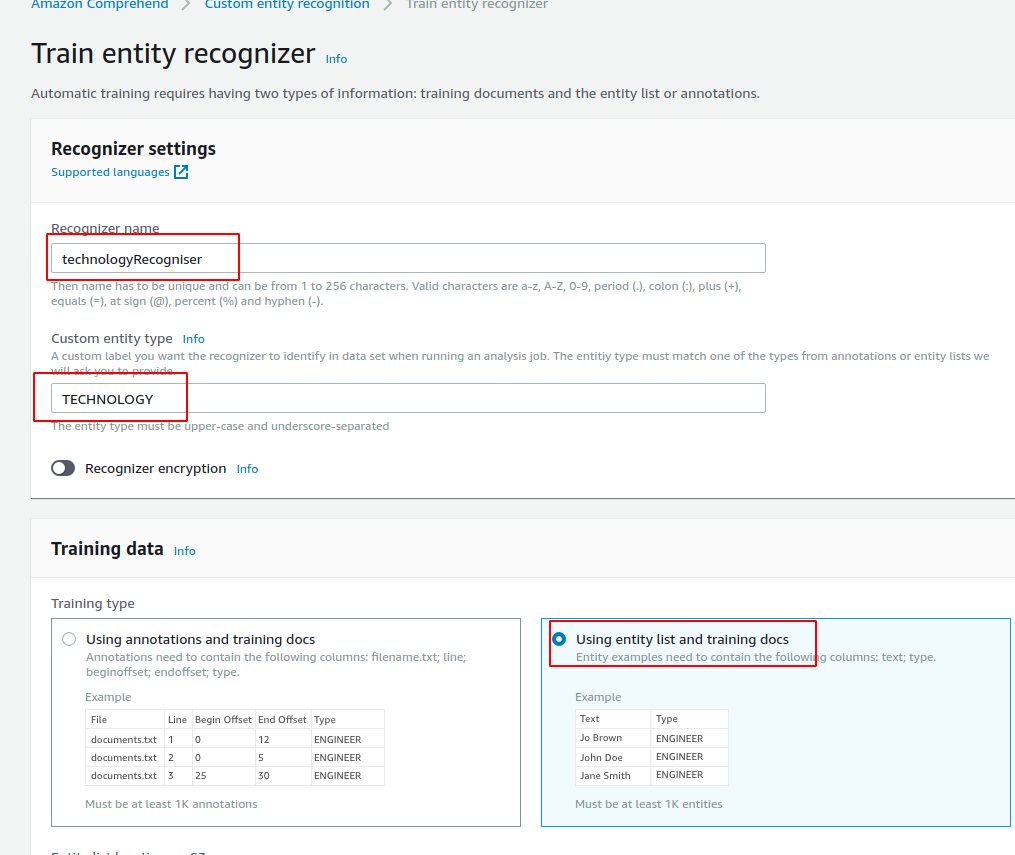
As you can see its just supplying the basic information, when then provide the location to the files we uploaded previously.
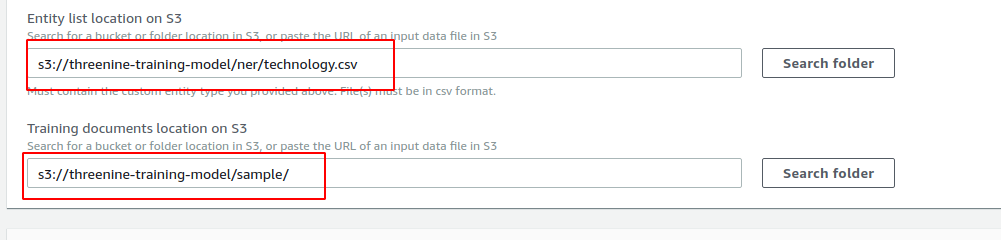
We then need to provide or create an S3 Role our recogniser will use to access the files. For the sake of simplicity of this article I simply created a role with Full Access, but your should probably define one with more security etc.
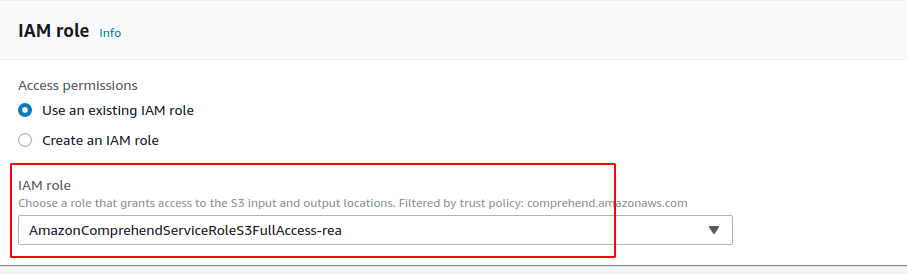
Once all the information, you can start to train your model, provided that every thing works well and AWS Comprehend can find enough samples per entity in your documents then it should take anywhere between an hour or even a day to train your depending on the volume of data.

Once your new recognizer has been successfully trained you should examine your results. The key elements you want to be looking at here is just how accurate your model is. As a rule of thumb I always try to ensure my model is at least above 90 in all the recogniser performance
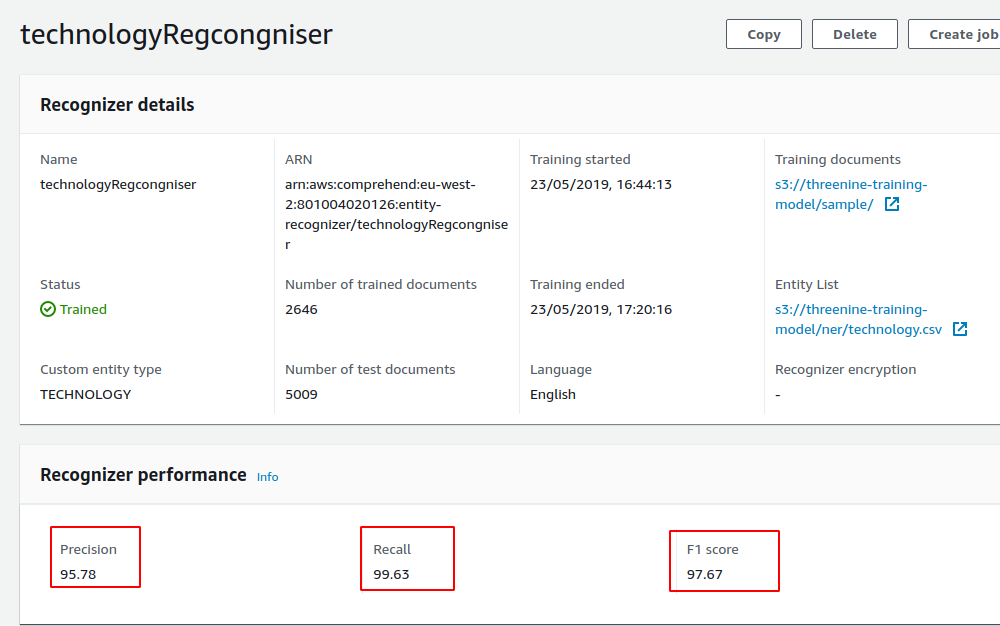
The primary reason for this, is that entity list are less accurate than annotated samples and later I will be using data derived from Entity List recognition to feed into my annotated list.
The above steps can be a really iterative process and you may have to go through it a number of times initially to get right. As programmers, if we do a task once we learn, we do it twice we get frustrated if we have to do it three times we automate it. Most of the time this is where we have the most fun, is where we automate these tasks, it also usually incurs for software engineering, this is also one the primary reason why I like to learn and take notes of the initial approaches so I can always successfully automate later.
Summary
We have learned the basics of NER and how we can use AWS Comprehend to create a Custom Entity Recognizer, we also created an initial Custom Entity Recogniser using AWS Comprehend.
Like with so many of my tutorial blog posts these days, this subject has turned out to be a long one, and I have decided to break it up into multiple parts in order for it to be easily understood.
If you would like to get notified when the next part of this series becomes available why not sign up to my Monthly Development Tips subscription it's free and I promise never to spam you!
- What is this Directory.Packages.props file all about? - January 25, 2024
- How to add Tailwind CSS to Blazor website - November 20, 2023
- How to deploy a Blazor site to Netlify - November 17, 2023